1大数据三大核心技术:拿数据、算数据、卖数据!
大数据的由来
对于“大数据”(Big data)研究机构Gartner给出了这样的定义。“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
1
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换而言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工纳迹碰”实现数据的“增值”。
从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘。但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
大数据需要特殊的技术,以有效地处理大量的容忍经过时间内的数据。适用于大数据的技术,包括大规模并行处理(MPP)数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统。
最小的基本单位是bit,按顺序给出所有单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
大数据的应用领域
大数据无处不在,大数据应用于各个行业,包括金融、 汽车 、餐饮、电信、能源、体能和 娱乐 等在内的 社会 各行各业都已经融入了大数据的印迹。
制造业,利用工业大数据提升制造业水平,包括产品故障诊断与预测、分析工艺流程、改进生产工艺,优化生产过程能耗、工业供应链分析与优化、生产计划与排程。
金融行业,大数据在高频交易、社交情绪分析和信贷风险分析三大金融创新领域发挥重大作用。
汽车 行业,利用大数据和物联网技术的无人驾州老驶 汽车 ,在不远的未来将走入我们的日常生活。
互联网行业,借助于大数据技术,可以分析客户行为,进行商品推荐和针对性广告投放。
电信行业,利用大数据技术实现客户离网分析,及时掌握客户离网倾向,出台客户挽留措施。
能源行业,随着智能电网的发展,电力公司可以掌握海量的用户用电信息,利用大数据技术分析用户用电模式,可以改进电网运行,合理设计电力需求响应系统,确保电网运行安全。
物流行业洞谈,利用大数据优化物流网络,提高物流效率,降低物流成本。
城市管理,可以利用大数据实现智能交通、环保监测、城市规划和智能安防。
体育 娱乐 ,大数据可以帮助我们训练球队,决定投拍哪种 题财的 影视作品,以及预测比赛结果。
安全领域,政府可以利用大数据技术构建起强大的国家安全保障体系,企业可以利用大数据抵御网络攻击,警察可以借助大数据来预防犯罪。
个人生活, 大数据还可以应用于个人生活,利用与每个人相关联的“个人大数据”,分析个人生活行为习惯,为其提供更加周到的个性化服务。
大数据的价值,远远不止于此,大数据对各行各业的渗透,大大推动了 社会 生产和生活,未来必将产生重大而深远的影响。
大数据方面核心技术有哪些?
大数据技术的体系庞大且复杂,基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据仓库、机器学习、并行计算、可视化等各种技术范畴和不同的技术层面。首先给出一个通用化的大数据处理框架,主要分为下面几个方面:数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。
数据采集与预处理
对于各种来源的数据,包括移动互联网数据、社交网络的数据等,这些结构化和非结构化的海量数据是零散的,也就是所谓的数据孤岛,此时的这些数据并没有什么意义,数据采集就是将这些数据写入数据仓库中,把零散的数据整合在一起,对这些数据综合起来进行分析。数据采集包括文件日志的采集、数据库日志的采集、关系型数据库的接入和应用程序的接入等。在数据量比较小的时候,可以写个定时的脚本将日志写入存储系统,但随着数据量的增长,这些方法无法提供数据安全保障,并且运维困难,需要更强壮的解决方案。
Flume NG
Flume NG作为实时日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时,对数据进行简单处理,并写到各种数据接收方(比如文本,HDFS,Hbase等)。Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和 Sink,source用来消费(收集)数据源到channel组件中,channel作为中间临时存储,保存所有source的组件信息,sink从channel中读取数据,读取成功之后会删除channel中的信息。
NDC
Logstash
Logstash是开源的服务器端数据处理管道,能够同时从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。一般常用的存储库是Elasticsearch。Logstash 支持各种输入选择,可以在同一时间从众多常用的数据来源捕捉事件,能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
Sqoop
Sqoop,用来将关系型数据库和Hadoop中的数据进行相互转移的工具,可以将一个关系型数据库(例如Mysql、Oracle)中的数据导入到Hadoop(例如HDFS、Hive、Hbase)中,也可以将Hadoop(例如HDFS、Hive、Hbase)中的数据导入到关系型数据库(例如Mysql、Oracle)中。Sqoop 启用了一个 MapReduce 作业(极其容错的分布式并行计算)来执行任务。Sqoop 的另一大优势是其传输大量结构化或半结构化数据的过程是完全自动化的。
流式计算
流式计算是行业研究的一个热点,流式计算对多个高吞吐量的数据源进行实时的清洗、聚合和分析,可以对存在于社交网站、新闻等的数据信息流进行快速的处理并反馈,目前大数据流分析工具有很多,比如开源的strom,spark streaming等。
Strom集群结构是有一个主节点(nimbus)和多个工作节点(supervisor)组成的主从结构,主节点通过配置静态指定或者在运行时动态选举,nimbus与supervisor都是Storm提供的后台守护进程,之间的通信是结合Zookeeper的状态变更通知和监控通知来处理。nimbus进程的主要职责是管理、协调和监控集群上运行的topology(包括topology的发布、任务指派、事件处理时重新指派任务等)。supervisor进程等待nimbus分配任务后生成并监控worker(jvm进程)执行任务。supervisor与worker运行在不同的jvm上,如果由supervisor启动的某个worker因为错误异常退出(或被kill掉),supervisor会尝试重新生成新的worker进程。
Zookeeper
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,提供数据同步服务。它的作用主要有配置管理、名字服务、分布式锁和集群管理。配置管理指的是在一个地方修改了配置,那么对这个地方的配置感兴趣的所有的都可以获得变更,省去了手动拷贝配置的繁琐,还很好的保证了数据的可靠和一致性,同时它可以通过名字来获取资源或者服务的地址等信息,可以监控集群中机器的变化,实现了类似于心跳机制的功能。
数据存储
Hadoop作为一个开源的框架,专为离线和大规模数据分析而设计,HDFS作为其核心的存储引擎,已被广泛用于数据存储。
HBase
HBase,是一个分布式的、面向列的开源数据库,可以认为是hdfs的封装,本质是数据存储、NoSQL数据库。HBase是一种Key/Value系统,部署在hdfs上,克服了hdfs在随机读写这个方面的缺点,与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
Phoenix
Phoenix,相当于一个Java中间件,帮助开发工程师能够像使用JDBC访问关系型数据库一样访问NoSQL数据库HBase。
Yarn
Yarn是一种Hadoop资源管理器,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。Yarn由下面的几大组件构成:一个全局的资源管理器ResourceManager、ResourceManager的每个节点代理NodeManager、表示每个应用的Application以及每一个ApplicationMaster拥有多个Container在NodeManager上运行。
Mesos
Mesos是一款开源的集群管理软件,支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等应用架构。
Redis
Redis是一种速度非常快的非关系数据库,可以存储键与5种不同类型的值之间的映射,可以将存储在内存的键值对数据持久化到硬盘中,使用复制特性来扩展性能,还可以使用客户端分片来扩展写性能。
Atlas
Atlas是一个位于应用程序与MySQL之间的中间件。在后端DB看来,Atlas相当于连接它的客户端,在前端应用看来,Atlas相当于一个DB。Atlas作为服务端与应用程序通讯,它实现了MySQL的客户端和服务端协议,同时作为客户端与MySQL通讯。它对应用程序屏蔽了DB的细节,同时为了降低MySQL负担,它还维护了连接池。Atlas启动后会创建多个线程,其中一个为主线程,其余为工作线程。主线程负责监听所有的客户端连接请求,工作线程只监听主线程的命令请求。
Kudu
Kudu是围绕Hadoop生态圈建立的存储引擎,Kudu拥有和Hadoop生态圈共同的设计理念,它运行在普通的服务器上、可分布式规模化部署、并且满足工业界的高可用要求。其设计理念为fast analytics on fast data。作为一个开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。Kudu不但提供了行级的插入、更新、删除API,同时也提供了接近Parquet性能的批量扫描操作。使用同一份存储,既可以进行随机读写,也可以满足数据分析的要求。Kudu的应用场景很广泛,比如可以进行实时的数据分析,用于数据可能会存在变化的时序数据应用等。
在数据存储过程中,涉及到的数据表都是成千上百列,包含各种复杂的Query,推荐使用列式存储方法,比如parquent,ORC等对数据进行压缩。Parquet 可以支持灵活的压缩选项,显著减少磁盘上的存储。
数据清洗
MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行计算,”Map(映射)”和”Reduce(归约)”,是它的主要思想。它极大的方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统中。
随着业务数据量的增多,需要进行训练和清洗的数据会变得越来越复杂,这个时候就需要任务调度系统,比如oozie或者azkaban,对关键任务进行调度和监控。
Oozie
Oozie是用于Hadoop平台的一种工作流调度引擎,提供了RESTful API接口来接受用户的提交请求(提交工作流作业),当提交了workflow后,由工作流引擎负责workflow的执行以及状态的转换。用户在HDFS上部署好作业(MR作业),然后向Oozie提交Workflow,Oozie以异步方式将作业(MR作业)提交给Hadoop。这也是为什么当调用Oozie 的RESTful接口提交作业之后能立即返回一个JobId的原因,用户程序不必等待作业执行完成(因为有些大作业可能会执行很久(几个小时甚至几天))。Oozie在后台以异步方式,再将workflow对应的Action提交给hadoop执行。
Azkaban
Azkaban也是一种工作流的控制引擎,可以用来解决有多个hadoop或者spark等离线计算任务之间的依赖关系问题。azkaban主要是由三部分构成:Relational Database,Azkaban Web Server和Azkaban Executor Server。azkaban将大多数的状态信息都保存在MySQL中,Azkaban Web Server提供了Web UI,是azkaban主要的管理者,包括project的管理、认证、调度以及对工作流执行过程中的监控等;Azkaban Executor Server用来调度工作流和任务,记录工作流或者任务的日志。
流计算任务的处理平台Sloth,是网易首个自研流计算平台,旨在解决公司内各产品日益增长的流计算需求。作为一个计算服务平台,其特点是易用、实时、可靠,为用户节省技术方面(开发、运维)的投入,帮助用户专注于解决产品本身的流计算需求
数据查询分析
Hive
Hive的核心工作就是把SQL语句翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce。可以将Hive理解为一个客户端工具,将SQL操作转换为相应的MapReduce jobs,然后在hadoop上面运行。Hive支持标准的SQL语法,免去了用户编写MapReduce程序的过程,它的出现可以让那些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户能够在HDFS大规模数据集上很方便地利用SQL 语言查询、汇总、分析数据。
Hive是为大数据批量处理而生的,Hive的出现解决了传统的关系型数据库(MySql、Oracle)在大数据处理上的瓶颈 。Hive 将执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。在Hive的运行过程中,用户只需要创建表,导入数据,编写SQL分析语句即可。剩下的过程由Hive框架自动的完成。
Impala
Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询分析。通过熟悉的传统关系型数据库的SQL风格来操作大数据,同时数据也是可以存储到HDFS和HBase中的。Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。Impala将整个查询分成一执行计划树,而不是一连串的MapReduce任务,相比Hive没了MapReduce启动时间。
Hive 适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据人员提供了快速实验,验证想法的大数据分析工具,可以先使用Hive进行数据转换处理,之后使用Impala在Hive处理好后的数据集上进行快速的数据分析。总的来说:Impala把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。但是Impala不支持UDF,能处理的问题有一定的限制。
Spark
Spark拥有Hadoop MapReduce所具有的特点,它将Job中间输出结果保存在内存中,从而不需要读取HDFS。Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
Nutch
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
Solr
Solr用Java编写、运行在Servlet容器(如Apache Tomcat或Jetty)的一个独立的企业级搜索应用的全文搜索服务器。它对外提供类似于Web-service的API接口,用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Elasticsearch
Elasticsearch是一个开源的全文搜索引擎,基于Lucene的搜索服务器,可以快速的储存、搜索和分析海量的数据。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
还涉及到一些机器学习语言,比如,Mahout主要目标是创建一些可伸缩的机器学习算法,供开发人员在Apache的许可下免费使用;深度学习框架Caffe以及使用数据流图进行数值计算的开源软件库TensorFlow等,常用的机器学习算法比如,贝叶斯、逻辑回归、决策树、神经网络、协同过滤等。
数据可视化
对接一些BI平台,将分析得到的数据进行可视化,用于指导决策服务。主流的BI平台比如,国外的敏捷BI Tableau、Qlikview、PowrerBI等,国内的SmallBI和新兴的网易有数等。
在上面的每一个阶段,保障数据的安全是不可忽视的问题。
基于网络身份认证的协议Kerberos,用来在非安全网络中,对个人通信以安全的手段进行身份认证,它允许某实体在非安全网络环境下通信,向另一个实体以一种安全的方式证明自己的身份。
控制权限的ranger是一个Hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的Hadoop生态圈的所有数据权限。可以对Hadoop生态的组件如Hive,Hbase进行细粒度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问HDFS文件夹、HDFS文件、数据库、表、字段权限。这些策略可以为不同的用户和组来设置,同时权限可与hadoop无缝对接。
简单说有三大核心技术:拿数据,算数据,卖数据。
2快三 彩票
当然不中奖啦。但是如果你买的是定位就中前面两个,只是奖金就大打折扣了。
3快三彩票如何推算
你好,这东西没人会预测。如果真会预测,早就成为亿万富翁了。
预测这东西我早就不信了,以前在网站上,经常看别人预测,结果买了,连一个号码都没对上。
楼主真要买,就权当是抱着娱乐的心态献爱心吧。
如果有人告诉你买什么号码,建议你都不要相信,因为我玩了几年房子跟老婆都玩没了。
PS:这东西真的不是好东西,洗心革面,重新做人,希望你能当机立断,不要存侥幸心理,果断戒赌。
写在最后,献给所有有缘看到这个答案的赌友或者赌友的亲人。
如果你赌博,不管是深陷其中还是刚尝到甜头,一定要努力自救。
赌博会使自己人生观和价值观出现巨大的扭曲,人会变的懒惰不堪。赌博会给家庭带来无尽的痛苦,会让那些爱你的人对你绝望,人们说吸毒败家,而赌博又何尝不是?当亲人一个个对你置之不理时,不要觉得世态炎凉,每个人都有自己的生活,何况再怎么旺的火也会被浇灭。因此好好工作,好好生活才是王道!
4马斯切拉诺国家队数据
哈维尔·阿莱杭德罗·马斯切拉诺是一位世界级的防守型中场。他的职业生涯从阿根廷河床俱乐部起步,带领他走上职业足球道路的正是日后执教皇马的名帅佩莱格里尼。他也很快获得了国家队处子秀机会,对手是乌拉圭。马斯切拉诺曾入选阿根廷青年队出战2004年雅典奥运,赢得金牌,也曾出战过世青杯。
2006年世界杯他也是国家队成员,可是未有太多机会表现,结果难逃被德国淘汰之厄运。不过随后却被英超的西汉姆联足球俱乐部收购旗下。起初球迷对他与国家队队友特维斯的加盟寄与厚望,但二人却迟迟未能发挥水平,加上球队的战绩急速下滑,更沦为保级份子,两人成为了代罪羔羊。
阿根廷奥运队决定把哈维尔·阿莱杭德罗·马斯切拉诺列入参加北京奥运的其中一名超龄球员,并成功协助球队达成2连霸,而自己就成为了唯一一位拥有2枚奥运金牌的阿根廷人。
代表国家队:出场71次,进2球
欧洲三大杯:出场45次,进1球
欧洲冠军联赛:出场33次,进0球
5快三大中小怎么玩呢
快三大中小走势图 - 用于分析快三大中小的趋势,选择平均线后走势下面会出现两条平均线,同颜色为10期均线,灰色为30期均线。折叠线:上下期开奖号码用一条线相连,以便更容易的查看号码的走向。
平均线:10期或30期的号码移动平均线,这是一种以更复杂的角度查看号码的走向,同颜色为10期均线,灰色为30期均线。
分段线:开奖号码每五期显示一条分段线,使号码横向展示更加清晰。
遗漏:开奖号码的遗漏数据,可让遗漏数据显示或隐藏于图表之中。
遗漏柱形图:开奖号码的当前遗漏数据直接用其他颜色显示出来,使遗漏情况清晰可见。
出现次数:指号码历史上总共开出的次数。
本期遗漏:指号码在上次开出之后到当前期已有多少期未出。
上期遗漏:指号码上次开出之前时的遗漏次数,也就是比当前期早一期的遗漏次数。
平均遗漏:指号码所有遗漏次数的平均值。
最大遗漏:指号码所有遗漏次数的最大值,鼠标停留在最大遗漏值时可查看最大遗漏发生在什么期。
欲出几率:指号码的本期遗漏除以平均遗漏。
快三大中小走势图下方可以设置每页显示多少期数据,另外还可以设置只看星期几开奖的数据。
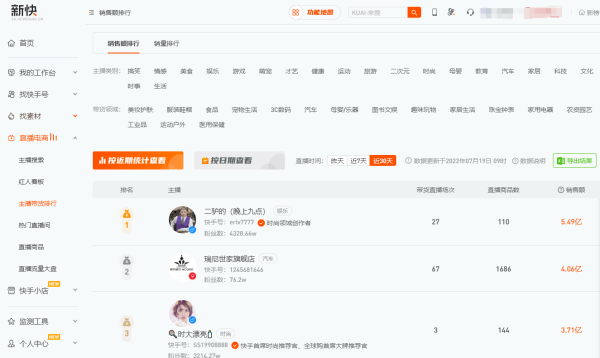
6快手主播数据排行榜怎么查?
可以通过新快数据查看各类榜单,包括达人榜、商品榜和快手官方热榜3大类目,提供多维榜单数据,帮助用户更好的了解行业风向,可以点击下方链接查看。
新快提供与直播电商相关的主播带货排行,包含直播销售额排行、直播销量排行、直播礼物收入排行,可以通过15+主播类型和带货领域筛选。
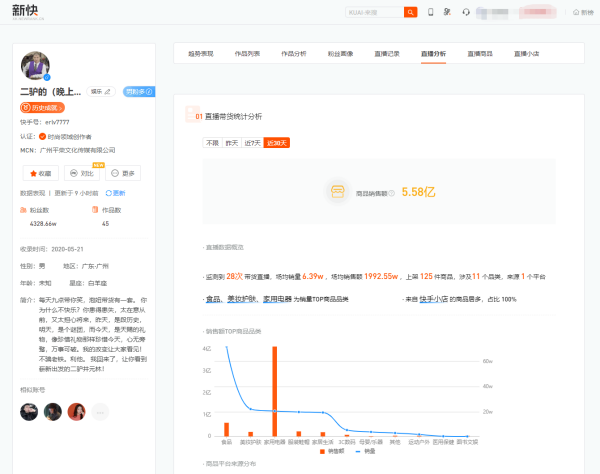
主播账号详情页包括账号整体趋势表现、短视频作品分析、粉丝画像及直播相关数据分析,最近还新上线了直播商品和直播小店数据。
7如何读懂现货交易中大盘里各种数据?
红买。绿卖伦敦金简介 伦敦金不是一种黄金的名称,而是一种黄金交易方式的名称。因最早起源于伦敦而得名。伦敦黄金市场并不是一个实际存在的交易场所,而是一个通过各大金商的销售网络连成的无形市场。伦敦金通常被称为欧式黄金交易。以伦敦黄金交易市场和苏黎世黄金市场为代表。 投资者的买卖交易记录只在个人预先开立的“黄金存折账户”上体现,而不必进行实物金的提取,这样就省去了黄金的运输、保管、检验、鉴定等步骤,其买入价与卖出价之间的差额要小于实金买卖的差价。这类黄金交易没有一个固定的场所。在伦敦黄金市场,整个市场是由各大金商、下属公司间的相互联系组成,通过金商与客户之间的电话、电传等进行交易;在苏黎世黄金市场,则由三大银行为客户代为买卖并负责结账清算。伦敦黄金市场上的黄金定价机制 伦敦的黄金定价是在"黄金屋"(Gold Room)进行的。所谓的“黄金屋”并不是用黄金建的屋子。而是一间在洛希尔公司总部专门用于交易黄金的办公室。从1919年9月12日,伦敦五大金行的代表首次聚会"黄金屋"开始,伦敦黄金市场定价制度就此形成,这种制度一直延续到了今天。五大金行每天制定两次金价,分别为上午10时30分和下午3时。此时各金商先暂停报价,由洛希尔公司的首席代表根据前一天晚上的伦敦市场收盘之后的纽约黄金市场价格以及当天早上的香港黄金市场价格定出一个适当的开盘价。其余四家公司代表则分坐在"黄金屋"的四周,立即将开盘价报给各自公司的交易室,各个公司的交易室则马上按照这个价格进行交易,把最新的黄金价格用电话或电传转告给其客户,并通过路透社把价格呈现在各自交易室的电脑系统终端。各个代表在收到订购业务时,会将所有的交易单加在一起,看是买多还是卖多,或是买卖相抵,随后将数据信息以简单的行话告诉给洛希尔公司的首席代表以调整价格。如果开盘价过高,市场上没有出现买方,首席代表将会降低黄金价格;而如果开盘价过低,则会将黄金价格抬高,直到出现卖家。定价交易就是在这样的供求关系上定出新价格的。定价的最后价格就是成交价格。定价的时间长短要看市场的供求情况,短则低于15分钟,长则可达1小时左右。之后,新价格就很快会传递到世界各地的交易者。 现在伦敦交易所里的5个定价银行是: 1、德意志银行2、香港上海汇丰银行-密特兰银行(美国汇丰银行)3、英国洛西尔投资银行4、美国共和银行5、加拿大枫叶银行伦敦的五大金商和苏黎士的三大银行等都在世界上享有良好的声誉,交易者的信心也就建立于此。伦敦金交易规则:1、伦敦金以美元标价,以英制盎司为计量单位。黄金报价以道琼斯国际报价为准,主要根据伦敦市场的现货黄金价格。一盎司等于31.106克。每日盘价为***美元 /1盎司黄金的价格。例如:大盘标出632.03/的数字,即为每盎司黄金632.03美元。2、伦敦金最低交易量为一手/张/单。一手等于100盎司。约等于三公斤黄金。3、保证金交易。只交少量保证金,即可进行大额交易。资金放大量约为100倍。对中小投资者是一个机会。北方公司要求的最低开户保证金是十万元港币。4、当日交易。开户当天即可交易,而且可以多次交易。T+05、可以双向交易。既可以买涨,也可以买跌。既可以先买,也可以先卖。因此无论金价如何走势,投资人始终有获利的空间。 6、即时买卖。只要价格在市,既可即时完成交易。不存在是否有人接单问题。不愁买不到,也不愁卖不出。7、黄金交易可以自设安全线,即交单时自定止损点和止赢点。因此在实际操作中可以将黄金交易的风险降到小于每日10%的跌幅。也就是小于股票每日的最大跌幅。同时由于黄金交易不设涨停板,因此黄金交易的日升幅率可以大于10%。日升幅达100%的情况也并不少见。伦敦金投资的特点: 一、 世界上第一大股票。全世界都在炒这种黄金,黄金交易量巨大,日交易量约为20万亿美元。因此没有任何财团和机构能够人为操控如此巨大的市场,完全靠市场自发调节。黄金市场没有庄家。市场规范,自律性强,法规健全。二、不用选股,操作简单:有无基础均可,即看即会。三、交易服务时间长:黄金交易时间是从早上9点到次日凌晨的2:30。早上9点至下午4点是亚洲盘交易时间,下午4点至晚上8:30是欧洲盘交易时间,晚上8:30至次日凌晨2:30为美洲盘交易时间。一般来说,黄金交易最活跃的时间为美洲盘,时间大致在晚上8点至次日凌晨1点之间。四、金价波动大:根据国际黄金市场行情,按照国际惯例进行报价。因受国际上各种政治、经济因素,以及各种突发事件的影响,金价经常处于剧烈的波动之中。在黄金市场上不存在牛市或熊市。不论金价是大起还是大落,对投资者而言都是机会。黄金市场讲究的是行情。行情就是每日大盘的落差,或波幅。即大盘最高价与最低价之间的差价。有差价就有行情,差价越大,行情越好。具体说:差价低于0.4% 时,行情较差。达到1%时行情就已经不错了,达到2%时相当不错。现在已经达到3%,因此是投资黄金的大好时机。五、有风险,更有机遇。常赌必输,专业必胜。六、资金结算时间短:当日可进行累积交易,提高投资基金比率,加大投资回报几率。 七、网上交易,交易方便:东南亚第一家开通现货黄金电子交易平台八、资金安全:只在银行与银行之间转换。
8国家统计局回应哪三大经济热点?
国家统计局14日公布了10月份中国经济数据,并回应了一系列经济热点问题。10月份中国经济表现如何?明年中国经济走势怎样?下一步房地产市场如何发展?

10月份中国经济表现如何?
国家统计局发布的数据显示,10月份国民经济继续保持稳中向好发展态势。记者注意到,就业、物价等指标表现较好,但也有部分指标有所放缓。

具体来看,1-10月份,全国城镇新增就业完成了1191万人,已经超额完成了年初1100万人的预定目标;1-10月全国CPI比去年同期上涨1.5%,处在年初制定的3%左右的物价调控目标之内;10月份社会消费品零售总额同比增长10.0%,增速比上月回落0.3个百分点;1-10月份,全国固定资产投资(不含农户)同比增长7.3%,增速比1-9月份回落0.2个百分点。
如何看待明年中国经济走势?
下一步经济运行走势会怎么样?刘爱华认为,从目前的情况看,前10个月的国民经济运行总体保持平稳态势。目前支持经济继续保持稳中向好的因素在累积增多,主要表现在供给、需求和预期三方面。
具体来看,一是供给体系的质量持续改善。先进产能在加快,落后产能逐渐退出,关系到下一步发展的优质供给也在较快增长;二是需求潜力逐渐释放。今年以来,一方面各部门促进消费稳定增长,另一方面注重发挥投资对优化供给结构的关键性作用,同时巩固外贸回稳的良好态势,形成了内外需求联动的良好格局;三是市场预期持续向好。10月份中国制造业采购经理指数是51.6%,已经连续15个月保持在临界点以上。

下一步房地产市场如何发展?
数据显示,1-10月份,商品房销售面积130254万平方米,同比增长8.2%,增速比1-9月份回落2.1个百分点。10月末,商品房待售面积60258万平方米,比9月末减少882万平方米。
刘爱华表示,自去年四季度“因城施策、因地制宜”的房地产调控政策实施以来,70个大中城市的15个热点城市的房价同比和环比涨幅都出现了回落,9月份的环比全部下降或者持平;同时,同比涨幅多个月持续回落。三四线城市出现类似特点,环比涨幅也在回落。这体现了去年以来房地产调控取得的成效。
9请帮忙给一些一次性筷子的数据
一次性筷子对树木的联系现在,很多小店和酒楼,都用一次性筷子。他们不知道,浪费了不少资源哩!
我的统计:假设一棵树可以制造30000条筷子(60树龄以上)就有15000双。可以进货1家酒楼供一年使用。但是,广州市有500000多家酒楼,就要 750000000双筷子,就要消耗50000棵60树龄的大树。要想到,这只是一年的消耗量呀!一年中有12个月,那么,就要消耗90亿双筷子.还有,这些小店和酒楼要成立好多年,那要消耗多少一次性筷子呀!我以前认为一次性筷子与树木没有关系的,但现在一算,一次性筷子与树木有着这么大的关系!做出可以供广州大小酒楼一个月用的筷子,竟然要消耗50000棵60龄的大树!50000棵,可不是一个小数哇!若假设一座森林(1平方米)有10万棵60树龄的大树,那么,在2个月内,这座森林就砍光了.你看,多么惊人的数目!请看下表。
月数
筷子双数
树木棵数
占1片森林的几分之几(一片森林按300万棵计)
1个月
750000000
50000
六分之一
2个月
1500000000
100000
三分之一
3个月
22500000000
150000
二分之一
从上表可以看出,一次性筷子的使用量很快地增加。仅三个月就达到300万树森林的一半!由此可看出,广州对一次性筷子的消耗量是多么的巨大!而不仅仅只有广州在用,还有全中国呢?
濒临枯竭的森林资源
现在,地球上的森林资源越来越少了。今天,世界上的森林总数仅剩下23亿公顷,但是,在200万年前,森林总数曾经达到79亿公顷。森林的消失,土地会增加沙漠化,平均每年世界损失耕地大约9%,在中国,最严重的是内蒙古的阿拉善盟,土壤的样子和田野表面的景色和太空船在火星表面拍的照片一模一样。这全是因为森林消失作的崇.有科学家计算过,每当森林消失1公顷,空气中的二氧化碳就增加0、001%,二氧化碳会使空气温度增加1度。由此恶性循环下去,那么,如此大量地消耗下去,地球的气温越来越高,地球就会成为宇宙中第二个金星!再过几年,下大雨动不动就发山洪,滑坡,泥石流……若没了森林,千万年后,地球的土壤变得和火星,木星差不多,空气中,氧气成了稀有气体,气温将会升到和金星差不多,没有水,没有动物,没有人,布满沙丘,岩石和山脉……简直让人不敢想象。而长期用一次
性筷子将会导致这种后果!
双重浪费
众所周知,筷子工厂生产出筷子后,通常要用大量清水冲洗,这样便会造成木头和水的双重浪费。这是值得一提的问题。假设一千克一次性筷子(2000双)要用100升水,那么,一所出产一次性筷子的厂要用多少水呢?咱们来合计合计。
月数
生产筷子数量(双)
用水吨数
1
49002
98.004
2
29870
59.74
3
4508
9.016
4
1000
2
5
4985
9.97
6
79653
159.306
7
9872
19.744
8
1345
2.69
9
9000
18
10
7654
15.308
11
2874
5.748
12
3356
6.712
合计:78个月
合计:203119双
合计:406.238吨
从上表可以看出,制造一次性筷子,用水量是多么的巨大!但如果筷子用完就这么丢了,污水用了就这么倒掉了,那么,地球上的水还可以给我们用几年?树木也会被砍光的。树木一旦被砍光,地球便会面目全非,好象左边的那幅火星表面图一个样。这是我们愿意看到的吗?虽然现在可以拿用过的一次性筷子去造纸,但此举没有得到推广。而且,只有纤维可以用,(占60%)其余的40%只好扔掉。日积月累,也是浪费。再加上中国目前的科学还不是不很发达,因此,一次性筷子本身所有的成分还不能得到好好利用。
减小一次性筷子的危害
有矛就有盾。一次性筷子的危害虽然不小,但是我们可以将它的危害性降低。
怎么个降低法呢?比如,我们出去吃饭,将一次性筷子带回家,消毒以后,可以重复使用许多遍。或者,我们自己带筷子去酒楼吃饭,一旦发现酒楼或小店用一次性筷子,就不用他们的一次性筷子。也可以向酒店经理建议不要用一次性筷子,并告诉他大量使用一次性筷子的危害。





